ブログの過去記事を整理したり、リライトしたりするのは大変な作業です。今回は、AIチャット(Gemini)と協力して、「WordPressからの記事抽出」と「ローカルAIによる自動推敲」を連携させるツールを作成しました。
ネット上のクラウド型AIチャットではなく、自分のPCで動く「ローカルAI」を採用した理由は次の3点です。
- プライバシー: 記事データが外部サーバーに送信されないため、未公開情報も安心して扱える。
- コストゼロ: 何度推敲を繰り返しても、API利用料(トークン代)は一切かからない。
- カスタマイズ性: モデルのパラメータやプロンプトを、納得がいくまで自由に調整できる。
Pythonの導入と準備
- インストール: 公式サイトまたはMicrosoft StoreからPythonをダウンロードし、インストールします。インストール画面で「Add Python to PATH」というチェックボックスに必ずチェックを入れてください。
- 実行環境の確認: コマンドプロンプトやPowerShellを開き、
python --versionと入力して数字が表示されれば準備完了です。
LM Studioの導入と設定
ローカルAIをグラフィカルに操作できる「LM Studio」を使用しました。LM Studio公式サイトからWindows版をダウンロードしてインストールします。
ここで重要になるのが、虫眼鏡アイコンから選んでダウンロードできる言語モデルの選定です。モデルの能力は、PCのスペックに大きく依存するので、以下の目安を参考にしてください。
モデル選びのポイント
- パラメーター数: 一般的なPCなら「8b」前後が快適です。「12b」以上はより賢いですが、動作が重くなります。
- 量子化 (Quantization): Q4_K_M や Q8_0 など。数値が大きいほど高精度ですが、メモリ(VRAM)を多く消費します。
- 推奨環境: 8bモデルならVRAM 8GB以上、12bモデルなら12GB〜16GBほどあるとスムーズです。
今回は、日本語の理解力と論理性に定評のある Google Gemma-3-12bを採用しました。
LM Studio側の必須設定
画面左側のフォルダーアイコン(マイモデル)からダウンロードした言語モデルを一覧表示できます。歯車アイコン(モデルのデフォルト設定を編集)で次の設定をします。
- Context Length(コンテキスト長): 記事が長い場合はより大きな数値に設定します。VRAM搭載量に依存するので、大きな数値を設定するとエラーが出ます。
- GPU Offload: グラフィックボードを積んでいる場合は「Max」に設定して、処理を高速化できます。
画面左側の「>-」アイコン(開発者)を開き、画面上部「モデルを選択してください」でダウンロードした言語モデルを選択します。ロードにはしばらく時間がかかります。
そして「Status: Stopped」をクリックして、サーバーを起動します(Status: Running)。これでPythonからAIを呼び出せるようになります。
WordPressの記事を取得するスクリプト
WordPressの「REST API」という機能を使って、過去記事をAIが読みやすい「Markdown(MD)」形式で保存します。
Markdown(MD)とは、 装飾を最小限の記号(#や*など)で表現するテキスト形式です。
事前準備: ライブラリのインストール
Windowsのターミナル(PowerShellなど)で以下のコマンドを実行し、必要なライブラリをインストールします。
pip install requests html2text
スクリプトの作成
メモ帳やVS Codeなどのエディタを開き、以下のコードを貼り付けて get_wp.py という名前で保存してください。 ※ SITE_URL の部分はご自身のサイトURLに書き換えてください。
import requests
import html2text
import os
import sys
import calendar
# カテゴリ名とタグ名をキャッシュする辞書(APIリクエスト回数を減らすため)
term_cache = {}
def get_term_name(base_url, taxonomy, term_id):
"""IDからカテゴリーやタグの名前を取得する"""
cache_key = f"{taxonomy}_{term_id}"
if cache_key in term_cache:
return term_cache[cache_key]
# カテゴリなら categories、タグなら tags エンドポイントを叩く
endpoint = "categories" if taxonomy == "category" else "tags"
url = f"{base_url}/wp-json/wp/v2/{endpoint}/{term_id}"
try:
resp = requests.get(url)
if resp.status_code == 200:
name = resp.json().get('name')
term_cache[cache_key] = name
return name
except:
pass
return None
def fetch_posts(base_url, year, month=None):
api_url = f"{base_url}/wp-json/wp/v2/posts"
if month:
last_day = calendar.monthrange(year, month)[1]
after, before = f"{year}-{month:02d}-01T00:00:00", f"{year}-{month:02d}-{last_day:02d}T23:59:59"
else:
after, before = f"{year}-01-01T00:00:00", f"{year}-12-31T23:59:59"
all_posts = []
page = 1
while True:
params = {'after': after, 'before': before, 'per_page': 100, 'page': page, '_embed': True}
response = requests.get(api_url, params=params)
if response.status_code != 200: break
posts = response.json()
if not posts: break
all_posts.extend(posts)
page += 1
return all_posts
def save_as_markdown(base_url, posts):
h = html2text.HTML2Text()
h.body_width = 0
output_dir = 'output_posts'
if not os.path.exists(output_dir): os.makedirs(output_dir)
for post in posts:
title = post['title']['rendered']
date = post['date']
content_md = h.handle(post['content']['rendered'])
categories = []
tags = []
# 方法1: _embedded から名前を探す
if '_embedded' in post and 'wp:term' in post['_embedded']:
for term_list in post['_embedded']['wp:term']:
for term in term_list:
if term['taxonomy'] == 'category':
categories.append(term['name'])
elif term['taxonomy'] == 'post_tag':
tags.append(term['name'])
# 方法2: それでも空の場合、IDリストから直接取得を試みる
if not categories and post.get('categories'):
categories = [get_term_name(base_url, 'category', cid) for cid in post['categories']]
if not tags and post.get('tags'):
tags = [get_term_name(base_url, 'post_tag', tid) for tid in post['tags']]
# Noneを除外
categories = [c for c in categories if c]
tags = [t for t in tags if t]
# 保存処理
filename = f"{output_dir}/{date[:10]}_{''.join(x for x in title if x.isalnum())[:30]}.md"
with open(filename, 'w', encoding='utf-8') as f:
f.write(f"---\ntitle: {title}\ndate: {date}\ncategories: {categories}\ntags: {tags}\n---\n\n{content_md}")
print(f"Saved: {title}")
if __name__ == "__main__":
SITE_URL = "https://kitaken.oops.jp" # 自分のサイトに変更
year = int(sys.argv[1]) if len(sys.argv) > 1 else 2024
month = int(sys.argv[2]) if len(sys.argv) > 2 else None
posts = fetch_posts(SITE_URL, year, month)
save_as_markdown(SITE_URL, posts)
実行方法
指定した年・月の記事を自動で巡回し、タイトルやタグ、本文を抽出してMDファイルとして保存します。
ファイルを保存したフォルダでShiftキーを押しながら右クリックし、「PowerShell ウィンドウをここで開く」を選択して、以下のコマンドを打ちます。
python get_wordpress_markdown.py 2024 12
実行すると、output_posts というフォルダの中に、2024年12月の記事が1つずつMarkdown形式で保存されます。
AIによる自動推敲スクリプト
次に、保存したファイルをLM Studioに読み込ませて、一気に推敲します。
こちらのコードも同様に refine_posts.py として保存して実行してください(※LM Studioのサーバーを起動しておくのを忘れずに!)。
import os
import sys
import glob
import json
import requests
import difflib
from pathlib import Path
import ctypes
# 設定
API_BASE_URL = "http://localhost:1234/v1" # LM Studioのデフォルト
MODEL_NAME = "google/gemma-3-12b-it-quantized" # 読み込んでいるモデル名
OUTPUT_DIR = "./refined_articles"
# スリープを抑制する定数
ES_CONTINUOUS = 0x80000000
ES_SYSTEM_REQUIRED = 0x00000001
# プロンプトの工夫
# パラメータが少ないモデル向けに、役割・制約・出力形式を厳密に指定
SYSTEM_PROMPT = """あなたはプロの紀行文編集者です。
読者がその場に行きたくなるような、臨場感と知的好奇心を刺激する文章に推敲してください。
## 推敲の指針:
1. 歴史・地形・文化的背景を1〜2文で自然に補足してください(例:地名の由来、建築様式の意義)。
2. 読者が旅の行程を追体験できるよう、接続詞を工夫して流れをスムーズにしてください。
3. 専門用語(例:石州瓦、曳家、日本海縦貫線)には、一般読者が理解できる短い説明を加えてください。
4. タイトルと見出しは、より魅力的で内容が伝わるものに改善してください。
## 制約事項:
- 画像タグ `` や URL、Frontmatter(---で囲まれた部分)は絶対に書き換えず、そのままの位置に保持してください。
- 出力は推敲後の本文のみを返してください。解説は不要です。"""
def get_refined_text(content):
headers = {"Content-Type": "application/json"}
payload = {
"model": MODEL_NAME,
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"以下のブログ記事を推敲してください:\n\n{content}"}
],
"temperature": 0.7,
"stream": True
}
full_response = ""
response = requests.post(f"{API_BASE_URL}/chat/completions", headers=headers, json=payload, stream=True)
print("推敲中...", end="", flush=True)
for line in response.iter_lines():
if line:
chunk = line.decode("utf-8")
if chunk.startswith("data: "):
data = chunk[6:]
if data == "[DONE]": break
try:
content_chunk = json.loads(data)["choices"][0]["delta"].get("content", "")
full_response += content_chunk
print(".", end="", flush=True)
except: pass
print("\n完了")
return full_response
def generate_diff_html(original, refined, filename):
diff = difflib.HtmlDiff(wrapcolumn=40).make_file(
original.splitlines(),
refined.splitlines(),
fromdesc='オリジナル',
todesc='推敲後'
)
output_path = Path(OUTPUT_DIR) / f"{filename}_diff.html"
with open(output_path, "w", encoding="utf-8") as f:
f.write(diff)
return output_path
def main():
if len(sys.argv) < 2:
print("Usage: python script.py <directory_path>")
return
#スリープを無効化
ctypes.windll.kernel32.SetThreadExecutionState(ES_CONTINUOUS | ES_SYSTEM_REQUIRED)
target_dir = sys.argv[1]
os.makedirs(OUTPUT_DIR, exist_ok=True)
files = glob.glob(os.path.join(target_dir, "*.md"))
for file_path in files:
print(f"\n処理中: {file_path}")
with open(file_path, "r", encoding="utf-8") as f:
original_text = f.read()
refined_text = get_refined_text(original_text)
# 差分HTML生成
diff_path = generate_diff_html(original_text, refined_text, Path(file_path).stem)
# 推敲済みファイル保存
with open(Path(OUTPUT_DIR) / Path(file_path).name, "w", encoding="utf-8") as f:
f.write(refined_text)
print(f"保存完了: {diff_path}")
#スリープ抑制を解除(デフォルトに戻す)
ctypes.windll.kernel32.SetThreadExecutionState(ES_CONTINUOUS)
if __name__ == "__main__":
main()
- Windowsのスリープ抑制: ctypes を使用し、大量の記事を処理している間にPCがスリープするのを防ぎます。
- プロンプトの工夫: 小規模なモデルでも迷わないよう、役割を与え、専門用語の解説など具体的に指示しています。このプロンプトは、小規模なモデル前提でAIチャットにどのようなものがよいか提案させ、各ライターにあわせて差し替えるとよいです。
- フォーマット保持: Markdownの画像タグやURLを破壊しないよう、厳格な制約を設けています。
- HTML差分出力: difflib を使い、どこが書き換わったかをブラウザで比較確認できるようにしました。
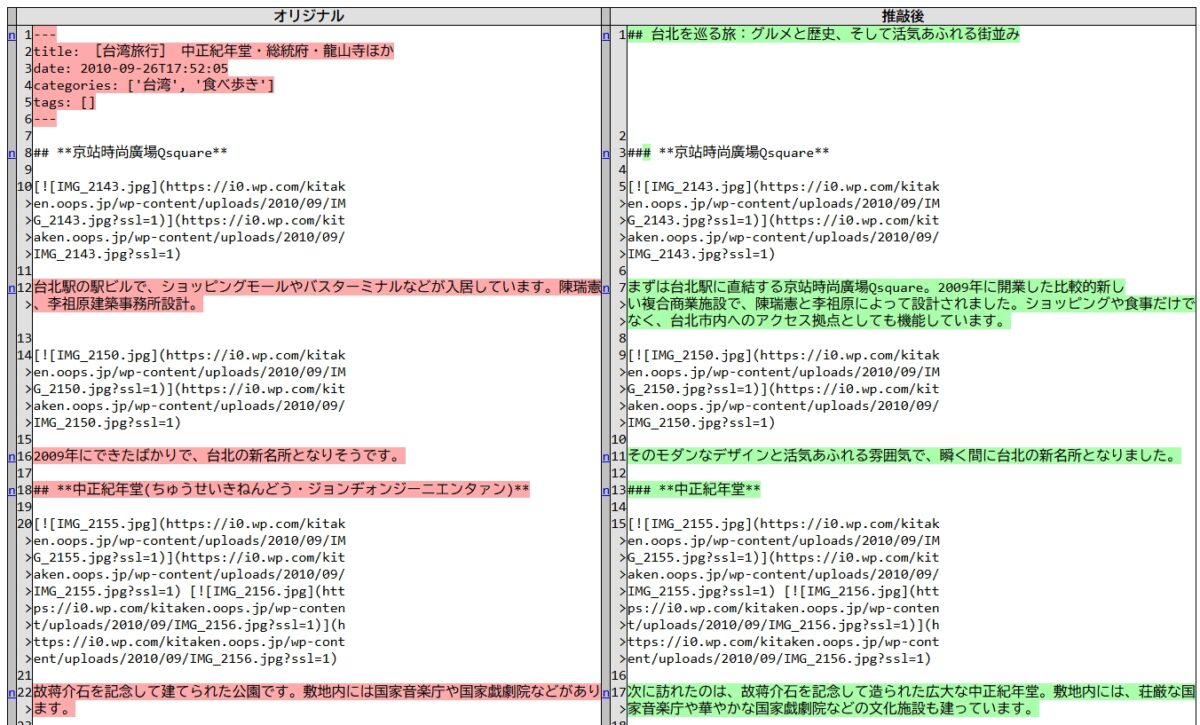
このように比較表をアウトプットしてくれました。
まとめ
今回のツール開発では、スクリプトの骨組みやエラーのデバッグに Gemini を活用しました。
「こんな機能が欲しい」と伝えるだけで、複雑なAPI連携やWindows固有の処理(スリープ抑制など)を瞬時に提案してくれ、開発効率が劇的に上がりました。
コメントを残す